There are several methods available which make data understanding very easy. The tree-based method is one of them. It has become one of the leading and most used method for understanding the data or information. This sort of techniques empowers insightful models with high precision, reliability and straightforwardness of comprehension. They are adaptable at dealing with any kind of issue close-by. There are different sorts of this system accessible and “Decision tree” is one of them.
What is “decision tree”?
Decision tree is a type of algorithm which is utilized in the learning procedure. It is mostly used in grouping systems. As the name recommends, this tree is utilized to help us in making choices. So, in other words, it is something that is a guide or schematic portrayal of conceivable outputs of a progression of relative choices.
Classes of this sort of tree
There are mainly 2 forms of this sort of tree are available, and those are “Binary variable” and “continuous variable” respectively.
- “Binary variable trees” are the ones which target variables which are binary. These are basically Yes or No types.
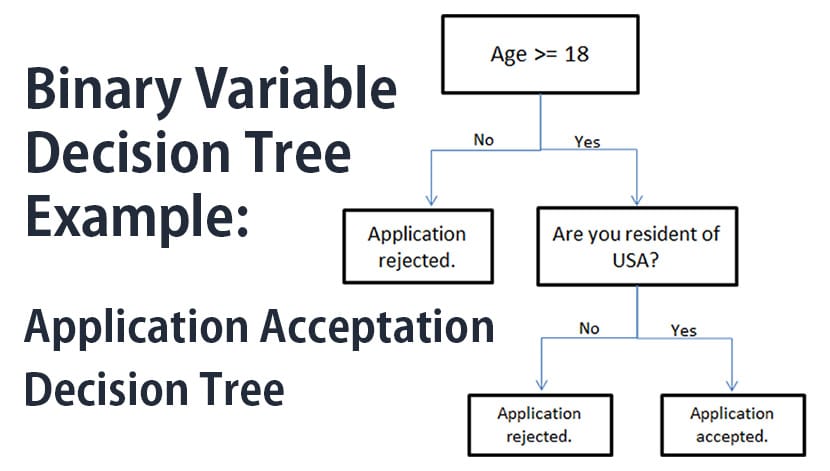
- “Continuous variable trees” are the ones which target variables which are persistent. It is also called “regression tree.”
How does it function?
It divides the data into smaller subgroups. Simultaneously, it develops associated decision tree. The arrangement of the tree begins by finding the element for “best split.” After splitting, the main hub or the “root” node is divided into “decision node” and “terminal node” respectively based on the types. These hubs are then further divided.
Sorts of wording identified with this sort of tree
- Root Node: his speaks to the entire example. It then gets divided into subgroups.
- Splitting: It is basically the procedure by which the entire example is separated into sub gatherings.
- Decision Node: It is the further sub hubs which are formed as a result of the splitting of the main group.
- Terminal Node: This sort of hub doesn’t experience part process.
- Sub-tree: The sub gathering or sub sort of the fundamental or the entire tree
- Pruning: It is the process of removing the sub hubs of a “decision node.” It basically omits the branches which have very less importance.
- Parent and Child Nodes: The hub which is separated into sub bunches is known as the parent hub, and the sub bunches are known as the child hub of the fundamental hub.
Symbols and what do they demonstrate
- Decision Node: Indicates the choice which is to be made. Represented as a square
- Chance Node: It demonstrates the various results which are uncertain. It is represented as a circle.
- Alternative Branches: It shows the conceivable outputs. It is represented as “<.”
- Rejected Alternative: Demonstrates the choices that were not chosen.
- Endpoint Node: Represents the final result.
How to draw it?
Drawing these sorts of trees are an entirely straightforward process. With a specific end goal to draw this sort of tree you need to do the followings:
- Start by selecting an appropriate medium for instance paper, whiteboard, programming that makes these sorts of trees.
- Then to represent the main decision, draw a square.
- Then proceed by drawing lines from that square to all the conceivable results and name the results appropriately.
- On the off chance that making “decision tree” is important then do that by drawing another square.
- You can make a circle in case the results are uncertain. This denotes the “chance node.” On the off chance that the issue is no longer present, leave it as blank.
- Now from every one of the previously mentioned hubs draws the conceivable arrangements and results.
- Now you go on expanding these lines until each line reaches the “end point.” Add triangles to represent the “endpoints.”
- Once reached the end, assign a value to each possible result. The values can be either a theoretical one or money related one.
Understanding terms
“Splitting” process: As we discussed above that this kind of tree divides the entire information based on several criteria. As a result of this subsets are formed which are fundamentally the parts of gatherings that have the same criteria. This dividing process continuous until perfect subsets are obtained with respect to the homogeneity. The criteria that are engaged with this procedure are:
- Gini Index: It measures the impurity of the information. So, in other words, it is the measure of the inconstancy. The value of this index decreases with the increase in the number of sub-trees.
- Data Gain: It is essentially the data got from the contrast between the entropy before the split and the average entropy after the split. This chooses the time when the parting process must be finished.
- Entropy: It is another criteria for selection. It portrays the arbitrariness of the data. The value of entropy and arbitrariness are directly proportional, i.e. if the value of entropy is high, then the arbitrariness is also high. Formula for calculating entropy: E = -p*log(p), where p is the probability.
- Pruning Process: It is utilized to improve the execution of the general tree that has been framed. Because of this procedure, the overall complication of the tree becomes less and consequently expanding the prescient intensity of the tree. Two kinds of this strategy are accessible, and these are “reduced error pruning” and “cost-complexity pruning” respectively. Among these two the later one is more beneficial.
Pros
- It distinguishes the relations which aren’t linear along with the relations which are linear
- Does not assume anything
- Easy to break down the information
- Simple visual portrayal
- Fewer endeavors are required for information arrangement
- Can be utilized for different outcomes
- Exactness is more
- It can use both the numerical as well as categorical data.
Cons
- Over fitting may result as a result of inappropriate tuning
- Exceptionally temperamental
- Challenges may emerge during working with continuous variables
- Cannot optimize the result.
So this kind of tree is very useful as it helps the common people to understand the data properly.